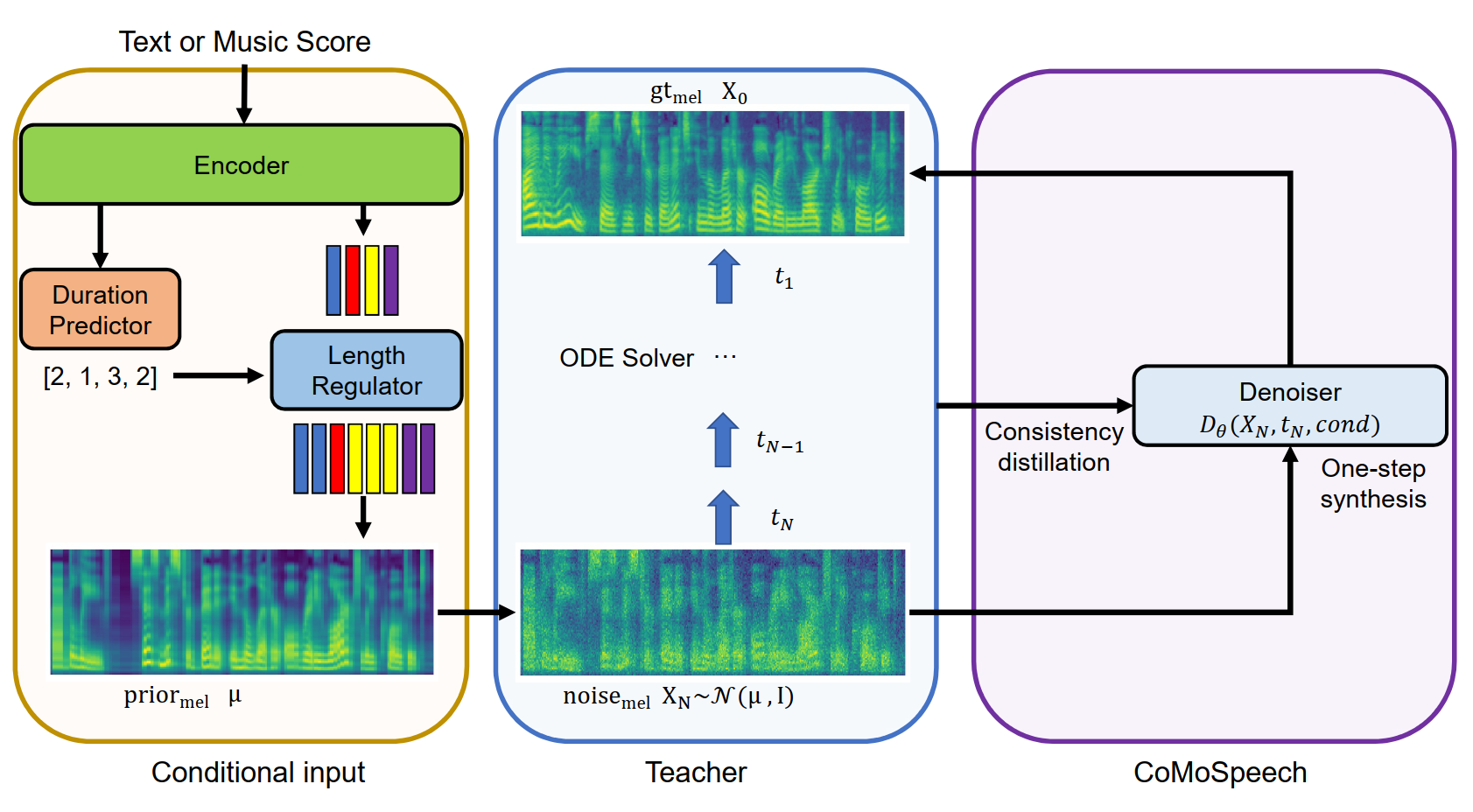
Denoising diffusion probabilistic models (DDPMs) have shown promising performance for speech synthesis. However, a large number of iterative steps are required to achieve high sample quality, which restricts the inference speed. Maintaining sample quality while increasing sampling speed has become a challenging task. In this paper, we propose a Consistency Model-based Speech synthesis method, CoMoSpeech, which achieve speech synthesis through a single diffusion sampling step while achieving high audio quality. The consistency constraint is applied to distill a consistency model from a well-designed diffusion-based teacher model, which ultimately yields superior performance in the distilled CoMoSpeech. Our experiments show that by generating audio recordings by a single sampling step, the CoMoSpeech achieves an inference speed more than 150 times faster than real-time on a single NVIDIA A100 GPU, which is comparable to FastSpeech2, making diffusion-sampling based speech synthesis truly practical. Meanwhile, objective and subjective evaluations on text-to-speech and singing voice synthesis show that the proposed teacher models yield the best audio quality, and the one-step sampling based CoMoSpeech achieves the best inference speed with better or comparable audio quality to other conventional multi-step diffusion model baselines.
Figure 1: An illustration of CoMoSpeech. Our CoMoSpeech distills the multi-step sampling of the teacher model into one step utilizing the consistency constraint.
Text-to-speech
The below audio samples show the comparison between Recordings, ground-truth (GT) mel + Vocoder, FastSpeech 2, DiffGAN-TTS, DiffSpeech, ProDiff, GradTTS, our Teacher and CoMoSpeech . Samples are selected from the test dataset of LJSpeech .
Sample 1: Now, as all books not primarily intended as picture-books consist principally of types composed to form letterpress,
Recordings
GT mel + Vocoder
FastSpeech 2 (NFE:1, RTF: 0.0017)
ProDiff (NFE:4, RTF:0.0097)
DiffGAN-TTS (NFE:4, RTF:0.0084)
Grad-TTS (NFE:50, RTF:0.1694)
DiffSpeech (NFE:71, RTF:0.1030)
Teacher (NFE:50, RTF:0.1824)
CoMoSpeech (NFE:1, RTF:0.0058)
Sample 2: And it is worth mention in passing that, as an example of fine typography,
Recordings
GT mel + Vocoder
FastSpeech 2 (NFE:1, RTF: 0.0017)
ProDiff (NFE:4, RTF:0.0097)
DiffGAN-TTS (NFE:4, RTF:0.0084)
Grad-TTS (NFE:50, RTF:0.1694)
DiffSpeech (NFE:71, RTF:0.1030)
Teacher (NFE:50, RTF:0.1824)
CoMoSpeech (NFE:1, RTF:0.0058)
Sample 3: than in the same operations with ugly ones.
Recordings
GT mel + Vocoder
FastSpeech 2 (NFE:1, RTF: 0.0017)
ProDiff (NFE:4, RTF:0.0097)
DiffGAN-TTS (NFE:4, RTF:0.0084)
Grad-TTS (NFE:50, RTF:0.1694)
DiffSpeech (NFE:71, RTF:0.1030)
Teacher (NFE:50, RTF:0.1824)
CoMoSpeech (NFE:1, RTF:0.0058)
Singing voice synthesis
The below audio samples show the comparison between Recordings, ground-truth (GT) mel + Vocoder, FFTSinger, HiFiSinger, DiffSinger, Our Teacher-SVS and CoMoSpeech-SVS. Samples are selected from the test dataset of OpenCpop.
Sample 1: 我晒干了沉默悔得很冲动
Recordings
GT mel + Vocoder
FFTSinger (NFE:1, RTF:0.0032)
HiFiSinger (NFE:1, RTF:0.0034)
DiffSinger (NFE:60, RTF:0.1338)
Teacher-SVS (NFE:50, RTF:0.1282)
CoMoSpeech-SVS (NFE:1, RTF:0.0048)
Sample 2: 能不能给我一首歌的时间
Recordings
GT mel + Vocoder
FFTSinger (NFE:1, RTF:0.0032)
HiFiSinger (NFE:1, RTF:0.0034)
DiffSinger (NFE:60, RTF:0.1338)
Teacher-SVS (NFE:50, RTF:0.1282)
CoMoSpeech-SVS (NFE:1, RTF:0.0048)
Sample 3: 小酒窝长睫毛是你最美的记号
Recordings
GT mel + Vocoder
FFTSinger (NFE:1, RTF:0.0032)
HiFiSinger (NFE:1, RTF:0.0034)
DiffSinger (NFE:60, RTF:0.1338)
Teacher-SVS (NFE:50, RTF:0.1282)
CoMoSpeech-SVS (NFE:1, RTF:0.0048)
Sample 4: 哦越过你划的线我定了勇气的终点
Recordings
GT mel + Vocoder
FFTSinger (NFE:1, RTF:0.0032)
HiFiSinger (NFE:1, RTF:0.0034)
DiffSinger (NFE:60, RTF:0.1338)
Teacher-SVS (NFE:50, RTF:0.1282)
CoMoSpeech-SVS (NFE:1, RTF:0.0048)
Ablation Studies of Consistency Distillation at Different Sampling Steps
The below audio samples show the comparison between Our teacher model (before consistency distillation) and CoMoSpeech (after consistency distillation) at different sampling steps.
Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition
CoMoSpeech (1 step)
Teacher (1 step)
We can observe that the one-step synthesized mel-spectrogram after consistency distillation significantly improve the quality by enriching many details, resulting in natural and expressive sounds.